Machine Learning
An Introduction
|
|
Prof. David Bernstein
James Madison University
|
|
| Computer Science Department |
| bernstdh@jmu.edu |

|
Motivation
- Review:
- Commonalities:
- The models have a known form that includes the number and
types of the terms, functions, and parameters
- The parameters are estimated by maximizing or minimizing a
"fit" function
Motivation (cont.)
- A Question:
- Can we "determine" the form of the model as well
as its parameters?
- The Answer:
- Most obviously, we can try different specific models
- Less obviously, we can specify a general class of models
and find the best within that class
- A Danger:
Some History
- Different Disciplines/Researchers:
- Researchers in statistics have studied this problem for
hundreds of years
- Researchers in artificial intelligence have studied this
problem for 50 years
- Researchers in data science and big data have studied this
problem for a few years
- The Resulting "Dispute":
- Which techniques belong in which discipline?
- Which disciplines have made the big discoveries and which
are just producing hype?
- Which terminology to use?
The Machine Learning "Perspective"
- Terminology:
-
Observations consist of features
- The response variable (or target) is
the feature being predicted and the other features
are predictors
- The system learns from the training set
- Types of Learning:
- Supervised - the "correct" answer is identified/labeled
in the training set and a loss function is
optimized
- Unsupervised - the system infers things from
the training set
- Reinforcement - the system attempts to maximize (using
dynamic programming techniques) the cumulative reward
(by balancing the "exploration of uncharted territory"
and the "exploitation of current knowledge")
The Machine Learning "Perspective" (cont.)
- Types of Response Variables:
- Continuous
- Categorical (or Classification)
- Quality of the Predictions:
- Defined using an evaluation function and measured
using a testing set
Data for Machine Learning
- Structured:
- Data in which the features are formatted according to a
pre-defined schema (e.g., tables, hierarchies)
- Unstructured:
- Everything else (e.g., images, audio files, video files,
text documents)
Artificial Neural Networks
- The Inspiration:
- A simple model of the brain consisting of a network
of neurons with axons at
each end
- A "Special" Aspect of Biological Neural Networks:
- There is a gap (called a synapse) between
the axons of different neurons (unlike graphs/networks in which
the edges/links/arcs "meet" at nodes/vertexes)
Artificial Neural Networks (cont.)
- The Inspiration (cont.):
- A message will be passed across the synapse if
the sum of the weighted input signals exceeds a
threshold (a process known as activation)
- Using the Inspiration:
- Construct a network consisting of input nodes, hidden nodes,
and output nodes
- Provide the network with inputs
- Adjust the parameters (i.e., learn) until the "best" outputs
are achieved (i.e., until the loss is minimized)
Artificial Neural networks (cont.)
An Example
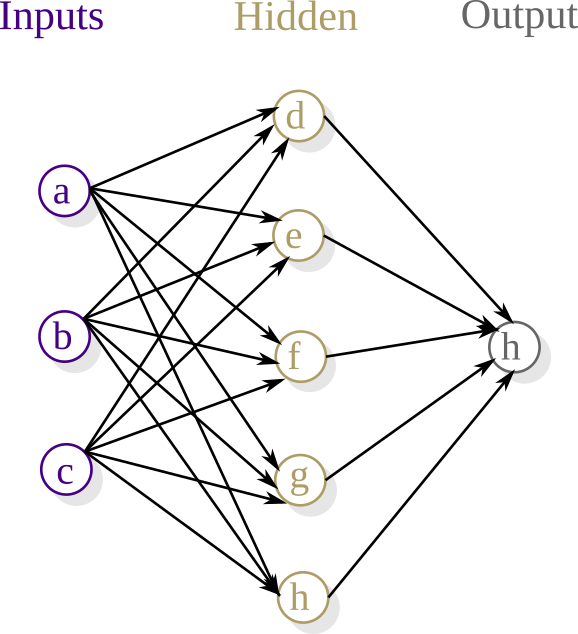
Artificial Neural Networks (cont.)
- Shallow vs. Deep Learning:
- Is really just about the number of hidden layers
- The Advantage of Deep Learning:
- The features needn't be specified, they can be learned
(through model tuning)
- The Disadvantages of Deep Learning:
- Needs more data
- The learning algorithm is more computationally demanding
ANNs with Supervised Learning
- Decisions to be Made when Constructing an ANN:
- Inputs and Outputs (and how to make them numerical)
- Shallow (i.e., one hidden layer) or Deep (i.e., multiple
hidden layers)
- Weighting Schemes and Activation Functions
- Loss Function
- Learning Algorithm (i.e., how to minimize the loss
function)
- The Result After Training:
- A weighted network that can be given inputs and will
produce predicted outputs
Some Supervised Classification Techniques
- Support Vector Machines:
- Find a hyperplane (e.g., a line
in \(\mathbb{R}^2\), a plane in
\(\mathbb{R}^3\)) \(N\) dimensions that
distinctly classifies the data (e.g., one color on one side of
the hyperplane and another color on the other)
- \(K\)-Nearest Neighbors (KNN):
- A point is classified based on the classification of
its K-nearest neighbors
- Naive Bayes Classifiers:
- A point is classified by assuming that each feature
contributes independently to the probability that point
belongs to a particular class (e.g., the color, shape and size of
a fruit contribute independently to the probability that it
is an apple)
Some Unsupervised Clustering Techniques
- \(K\)-Means:
- A point is classified based on the classification of
its K-nearest neighbors
- Hierarchical Clustering:
- Groups data into a dendogram (i.e., a multi-level
tree of clusters)